
잡동사니
Ceph의 Architecture 이해 본문
안녕하세요. yeTi입니다.
오늘은 쿠버네티스를 하다보면 접하게되는 rook-ceph 중 ceph에 대해서 알아보겠습니다.
Ceph이란?
Ceph은 PC단위를 Ceph Node로 storage를 clustering 해주는 서비스입니다.
Intro to Ceph에 따르면 Ceph Storage Cluster를 구성하기 위해서는 Ceph Monitor, Ceph Manager, Ceph OSD(Object Storage Daemon)가 하나이상 있어야 하고 Ceph File System client를 사용하려면 Ceph Metadata Server가 있어야 합니다.

각각의 데몬들은 다음과 같은 역할을 합니다.
Monitors: Ceph Monitor (
ceph-mon)는monitor map,manager map,OSD map,MDS map,CRUSH map과 같은 cluster의 상태정보를 구성합니다.HA를 위해서는 3개 이상 구성하는것을 추천합니다.Managers: A Ceph Manager daemon (
ceph-mgr)는storage utilization이나performance,system load와 같은Ceph cluster의 상태정보를 추적합니다. HA를 위해서 2개 이상 구성하는것을 추천합니다.Ceph OSDs: A Ceph OSD (object storage daemon,
ceph-osd)는 데이터를 저장하고, replication이나 recovery, rebalancing을 수행합니다. 또한 Ceph OSD 데몬들의 heartbeat를 Ceph Monitors and Managers에 제공하기도 합니다. HA를 위해서 3개 이상 구성하는것을 추천합니다.MDSs: A Ceph Metadata Server (MDS,
ceph-mds)는 Ceph File System의 메타데이터를 저장합니다.(Ceph Block Devices나 Ceph Object Storage는 MDS를 사용하지 않습니다.)Ceph Metadata Server를 통해POSIX file system 사용자는Ceph Storage Cluster에 큰 부담을주지 않으면서 기본 명령을 실행할 수 있습니다.
Architecture
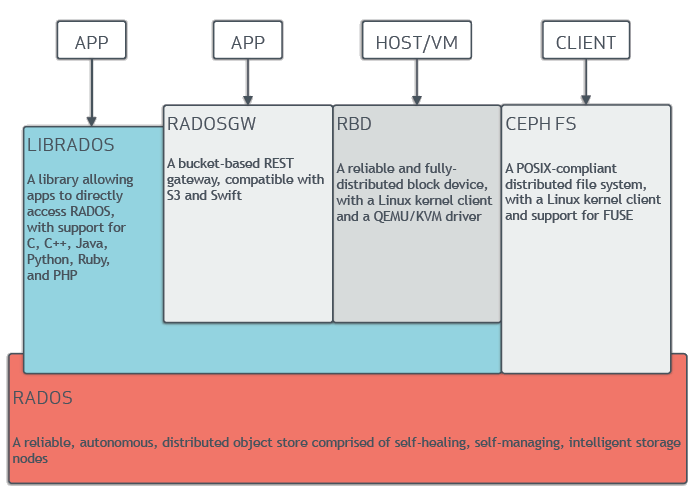
위 그림과 같이 RADOS를 기반으로 데이터를 Read/Write하고, librados라는 라이브러리를 제공하여 RADOS에 직접 접근할 수 있도록 제공합니다. 또한, RadosGW, RBD, CephFS와 같은 ceph clients를 제공하여 Ceph Storage에 접근할 수 있는 인터페이스를 제공합니다.
RADOS (Ceph Storage Cluster)
Scalable, Reliable Storage Service for Petabyte-scale Storage Clusters로 Ceph의 데이터 접근에 대해 근간을 이루는 서비스입니다. 즉, Ceph에서 object를 읽고 쓸때 RADOS를 사용합니다.
RADOS에 대한 자세한 내용은 RADOS-PDSW에 CRUSH에 대한 자세한 내용은 CRUSH를 참고하면 됩니다.
Ceph Clients
Ceph Client는 다양한 서비스 인터페이스를 제공하여 외부에서 데이터를 관리할 수 있도록 제공합니다.
Object Storage (RadosGW)
Amazon S3 및 OpenStack Swift와 호환되는 인터페이스가있는 RESTful API 서비스를 제공합니다.
Ceph Object Storage구성 및 접속해보기를 참고하시면 실제 구성한 예제를 보실 수 있습니다.
Block Device (RBD)
스냅샷 및 clone 기능을 가지고 있는 block device 서비스를 제공합니다. 이는 resizable하고 thin-provisioned 합니다.
File System (CephFS)
마운트 또는 사용자 공간에서 파일 시스템으로 사용할 수있는 POSIX 호환 파일 시스템을 제공합니다.
Pools
Ceph storage 시스템은 객체 저장을 위해 논리적인 파티션인 Pools이라는 개념을 지원합니다.

Ceph client는 Ceph Monitor가 가지고 있는 cluster map을 조회하고 저장할 객체를 pool에 전달합니다. 그러면 pool의 크기나 replica의 수, CRUSH 룰, placement group 수에 따라 ceph이 데이터를 저장하는 방법이 결정됩니다.

각 pool은 다수의 placement group을 가지고 있는데, ceph client가 pool에 객체를 전달하면 CRUSH는 객체를 placement group에 매핑합니다.
Placement Group (PG)
Placement Group은 Ceph Client와 Ceph OSD Daemon간 loose coupling하는 역할을 합니다. 이는 Ceph OSD Daemon이 동적으로 추가/삭제 되더라도 rebalance를 동적으로 할 수 있도록 해줍니다.
Ceph Metadata Server (MDS)
Ceph File System Service에는 Ceph Storage Cluster와 함께 배포 된 Ceph Metadata Server가 포함됩니다.
Replication
일반적인 쓰기 시나리오에서 클라이언트는 CRUSH 알고리즘을 사용하여 객체를 저장할 위치를 계산하고 객체를 pool 및 PG에 맵핑 한 다음 CRUSH map을보고 PG의 primary OSD를 식별합니다

클라이언트는 primary OSD에서 식별 된 PG에 객체를 씁니다. 그런 다음 자체 CRUSH 맵 사본이있는 primary OSD는 replication를 위해 2차 및 3차 OSD를 식별하고 2차 및 3차 OSD에서 해당 PG로 객체를 replication하고 객체를 확인하면 클라이언트에 응답합니다.
Sharding

ABCDEFGHI를 가진 NYAN 객체가 pool에 기록할 때, 삭제 인코딩 기능은 컨텐츠를 3으로 나누는 것만으로 컨텐츠를 3 개의 데이터 chunk로 분할합니다. 데이터는 각각 ABC, DEF, GHI로 나눠지는데, 내용 길이가 K의 배수가 아닌 경우 내용이 채워집니다. 이 함수는 두 개의 코딩 chunk도 만듭니다. 네 번째는 YXY의 경우와 다섯 번째는 QGC의 경우입니다. 각 청크는 작동 세트의 OSD에 저장됩니다. Chunk는 이름 (NYAN)은 동일하지만 다른 OSD에있는 오브젝트에 저장됩니다. Chunk가 작성된 순서는 보존되어야하며 이름 외에 객체의 속성으로 저장됩니다.
노드 추가

Ceph OSD Daemon을 Ceph Storage Cluster에 추가하면 cluster map이 새로운 OSD로 업데이트되고 PG ID를 다시 계산하면서 클러스터 맵이 변경됩니다. 결과적으로 계산에 대한 입력이 변경되므로 객체 배치가 변경됩니다.
위 그림은 OSD3가 추가되면서 모든 PG가 아닌 일부 PG가 기존 OSD (OSD 1 및 OSD 2)에서 새로운 OSD (OSD 3)로 마이그레이션하는 rebalancing 프로세스를 보여줍니다. Rebalancing에도 CRUSH는 안정적일 뿐만 아니라 대부분의 PG는 원래 구성으로 유지되며 각 OSD는 약간의 용량을 추가하므로 재조정이 완료된 후 새 OSD에 load spike가 없습니다.
'IT > Big Data' 카테고리의 다른 글
| Ceph Object Storage구성 및 접속해보기 (3) | 2020.07.14 |
|---|---|
| [SPSS] 연관규칙 분석을 활용한 화장품 구매 패턴 분석 (3) | 2018.12.13 |
| [SPSS] 군집분석을 활용한 카드 고객 분류 (0) | 2018.11.30 |
| [SPSS] 의사결정나무기법을 활용한 경매 경쟁 예측 (0) | 2018.11.29 |
| [SPSS] 인공신경망 기법을 활용한 사고피해 정도 예측 (0) | 2018.11.29 |


